
Can Databricks close the gap with Snowflake?
Security Authorization Policy Management Comparison
Earlier this month (5/3/23), Databricks purchased Okera in an attempt to close the security gap between itself and Snowflake.
Can Databricks close that gap? How hard will it be to integrate Okera into delta lake?

The short answer is No. The why is in the details (below).
Let’s look at
1. How Snowflake does Policy Management
2. How Databricks does Policy Management
3. The Gap
4. What Databricks is trying to do to close the gap
5. The Workarounds* the administrator will need to do to close the gap until Databricks gets there.
* – caution, workarounds are time-consuming, error prone, have to go through CorpSec scrutiny and will lead to unintended access granted if not done correctly.
How Snowflake does Policy Management
Snowflake was built with security in-mind literally from the ground up; it is natively part of the stack. As it relates to authorization policy controls (which users can do which things to which assets), with Snowflake you create policies based on resources or data classification.
Here is a handy url to quickly get you spun up: Access control Overview
Within this, you see the traditional GRANT that allows privileges to be granted to roles (which are in turn other roles, or users) for a given resource.
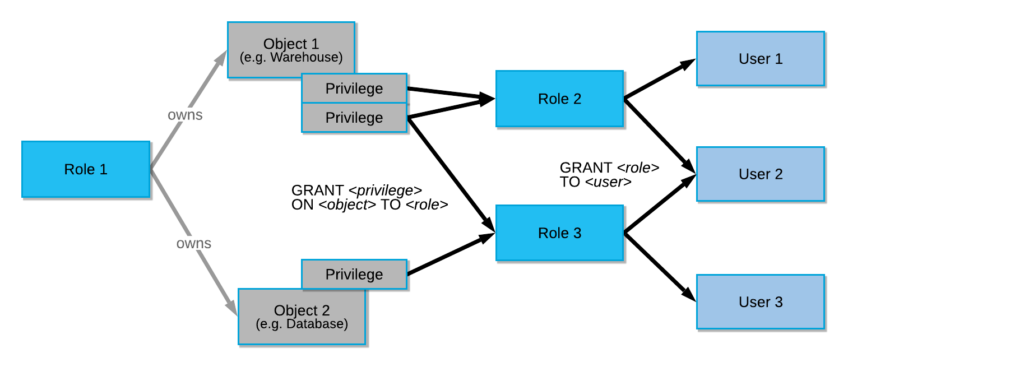
Resources can be any tables, view, udf, etc.:
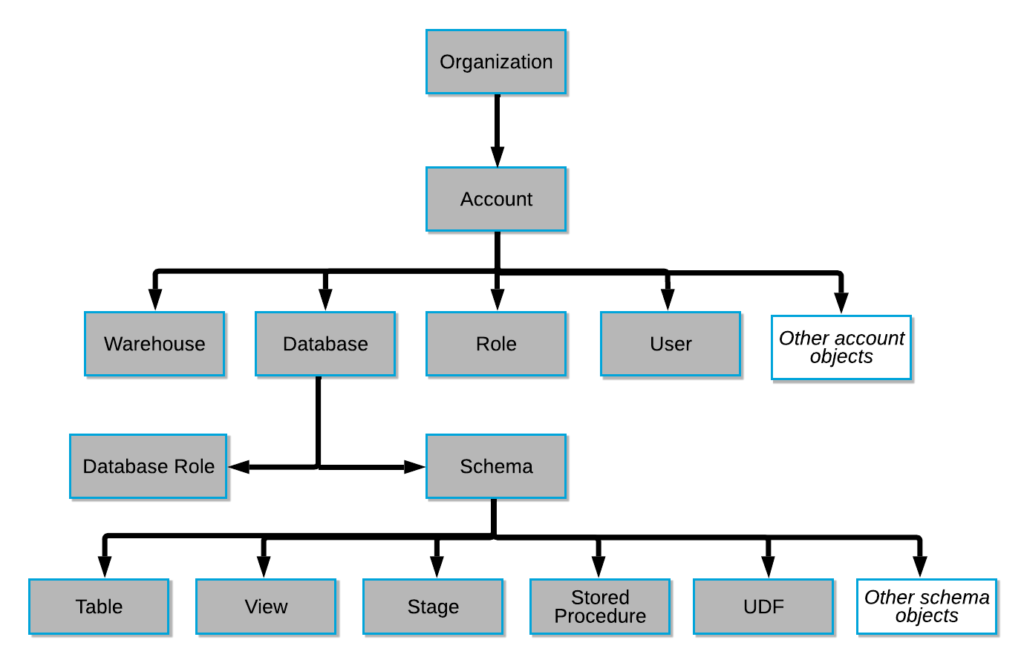
Snowflake also took it a step further, and they allow data to be classified and tagged, with policies created on the data classification (at the column level) that allows that data to be allowed/denied/masked. The column level distinction is extremely important – it is very common for PII data to mixed in tables with non-PII data. They also have a row level filtering capability. This is very important as well, as you often find yourselves not wanting to grant access to all users for all rows on a given fact table.
Here is the data governance primer url to quickly get you spun up: Data Governance Primer
There are several key points here:
1. Data Classification (url here), the classifier, which is called by function EXTERNAL_SEMANTIC_CATEGORIES , derives from the data columns which may be PII data. It is driven by a probabilistic algorithm that looks for the existence of such data.
2. Object Tagging (url here) – you the data engineer tag the data by type. You create your own tags and you may have multiple sensitive types ( CPNI, HIPAA, PCI, PII, etc.) depending on your business and you may also want to have non-sensitive types. Tagging allows you to search and set policy based on data classification type.
3. Set your column and row level policies (url here). Now that we have the data tagged, we can set policies based on those tags. I can say for all my CPNI data, only allow access for users with CPNI role.
How Databricks does Policy Managemennt
In Databricks SQL, users are granted access to a resource using the grant command (url here).
The syntax is:
GRANT privilege_types ON securable_object TO principal;
For example:
GRANT CREATE ON SCHEMA myschema TO `alf@melmak.et`;
GRANT ALL PRIVILEGES ON TABLE forecasts TO finance;
GRANT SELECT ON TABLE sample_data TO USERS;
This is not much different than Snowflake resource based granting, the exception being with Databricks you are granting to users and groups and not to roles. Roles do give you more flexibility, but the bigger gap is the lack of column masking and row filtering, which is noticbly absent..
The Gap
Here is a list of the native capabilities of each platform:
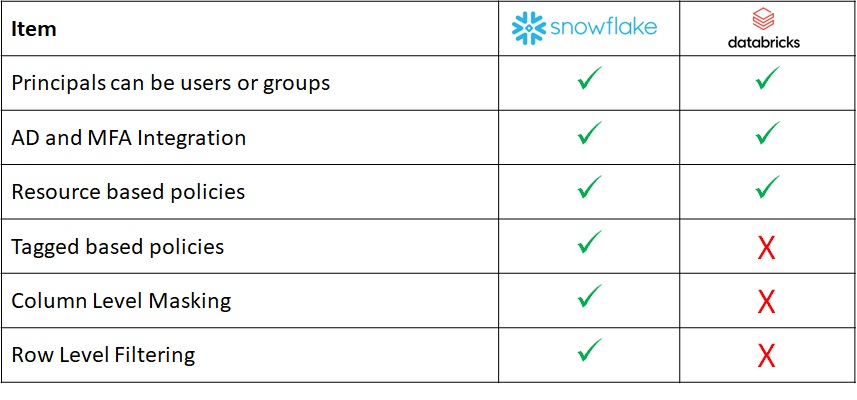
What Databricks is trying to do to close the gap?
Recognizing that they were lacking, in May 2023, Databricks purchased Okera. Okera is a roughly 80-person firm.
Okera is a 3rd party API-based tool that finds, tags and registers data by classification across a number of platforms that intercepts queries and provides allow/deny based on tag.
Databricks did get Lars George – apache member, former author of hbase (thank you for the offheap bucketcache back in the day!) with the purchase of Okera. Lars is tasked with integrating the data classification and tagging into Unity Catalog.
The Okera acquisition is definitely a step in the right direction, but Lars and team have their work cut-out for him. He has to:
=> Integrate the Okera Data Classification Discovery Tool into Unity Catalog
=> Integrate the Okera Authorization code into Unity Catalog
=> Integrate the Okera code to sit on the Delta file format
=> Have all the spark dev team utilize the Okera code prior to persisting or reading anything
It’s going to be a bit before all that happens..
Workaround #1 – Column Masking
There are two options available to Databricks users to hide sensitive columns. If you are a Databricks Data Engineer, make sure you use this for all sensitive data (PII, CPNI, PCI, HIPAA, etc.).
1.UDF – create a user defined function (https://www.databricks.com/blog/2020/11/20/enforcing-column-level-encryption-and-avoiding-data-duplication-with-pii.html). Here a UDF is utilized to encrypt the data prior to inserting to table. A view with a decryption is available for privileged users to decrypt.
2.Beginning with DBR 12.2, you can create a table that stores the actual value and a view that the regular users will use. In the view, users select against a mask. Ensure users only select against the view, not the actual table.
create table customer ( acctid int, fname varchar(20), lname varchar(20), ssn varchar(11));
create view customer_vw as select acctid, fname, lname, mask(ssn) from customer;
Pay attention to not miss any sensitive columns!
Workaround #2 – Row Filtering
You have to change your data model to separate the sensitive rows (and join if you want both) or use views. Here is the views way to do it.
Take the telco example. Some users can see all data. Other users should only see non-government. You have to split into two tables and users who see all will need to join the two tables or create a view, only allow users access to that view and ensure the view does the filter so government can not be seen:
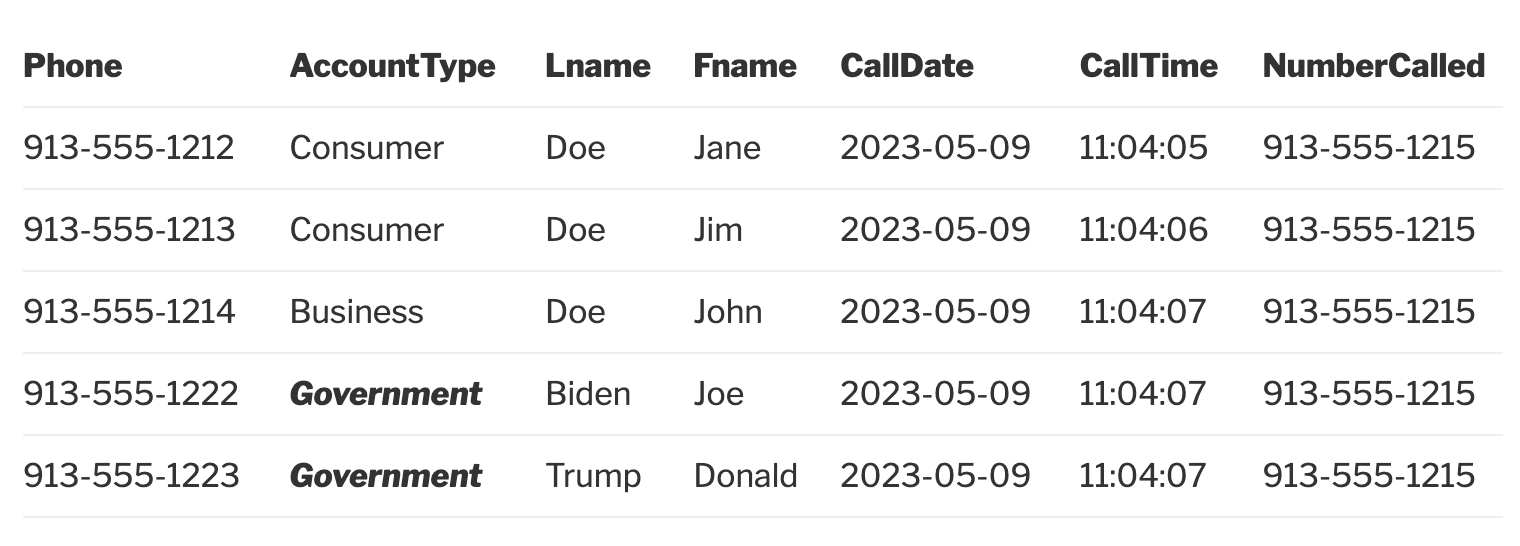
create view as select * from cdr where accounttype != “Government”
Make sure non-privileged users can only hit the view!
Make sure all sensitive data comes in that matches where clause. E.g. Government, not government. Alternatively, catch more things in the where clause:
create view as select * from cdr where accounttype != “Government” or accounttype != “government” or accounttype != “Govt” accounttype != “govt”
Workaround #3 – No Tagging
There is no work-around here. You are going to need a 3rd party tool or create your own set of metadata tables.
Summary
Snowflake Out of The Box has security built-in, it’s part of the system.
Databricks has invested by purchasing Okera in May 2023 to try to close that gap. It will take some time to get there. I’m guessing it will be in the 12-18 month time period, but that is just a guess.
Until that happens, Databricks customers will either need to (a) invest in a 3rd party authorization platform like Okera or Privacera that intercepts queries or (b) Databricks customers will need to utilize workarounds to achieve use cases while ensuring security.
There are three inherit drawbacks:
1. 3rd Party Addons take time and $
2. Work-arounds take time ($) (the scoping would be like 2 guys + extra guy per 20-30k tables)
3. 3rd Party Addons and work-arounds are inherently prone to human error (risky)
A boss or a bosses boss will probably have you do the ole’ build (workaround scripting) vs. buy (3rd party query interceptor) to close the gap. Due your diligence..
If you are a Databricks administrator, just be very careful. You should either get really serious about switching to Snowflake or get really serious about setting up automation to protect yourself. Within your scripting framework, you will want to develop it such that the script is taking input from some auditable delimited file (that you can get buy-off from your CorpSec) such that the right privileges are applied to the right objects for the right users/groups 100% of the time. I’d also have someone double-check my work / share that risk with me.